DAPPLE: A Pipelined Data Parallel Approach for Training Large Models
Abstract
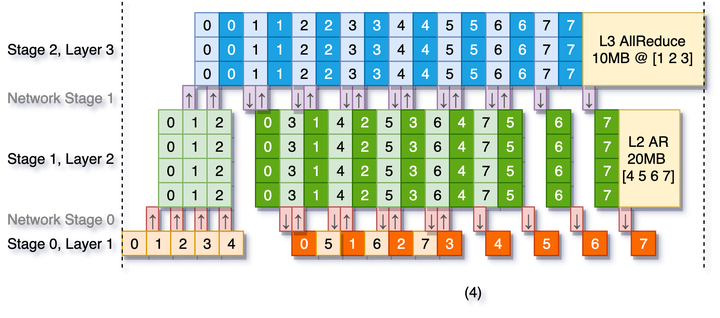
It is a challenging task to train large DNN models on sophisticated GPU platforms with diversified interconnect capabilities. Recently, pipelined training has been proposed as an effective approach for improving device utilization. However, there are still several tricky issues to address: improving computing efficiency while ensuring convergence, and reducing memory usage without incurring additional computing costs. We propose DAPPLE, a synchronous training framework which combines data parallelism and pipeline parallelism for large DNN models. It features a novel parallelization strategy planner to solve the partition and placement problems, and explores the optimal hybrid strategy of data and pipeline parallelism. We also propose a new runtime scheduling algorithm to reduce device memory usage, which is orthogonal to re-computation approach and does not come at the expense of training throughput. Experiments show that DAPPLE planner consistently outperforms strategies generated by PipeDream’s planner by up to 3.23x under synchronous training scenarios, and DAPPLE runtime outperforms GPipe by 1.6x speedup of training throughput and reduces the memory consumption of 12% at the same time.