L.E.R Academic
L.E.R Academic
About
Publications
Experience
Projects
Posts
Home
Light
Dark
Automatic
English
中文 (简体)
Data Parallelism
CSE203B: Linear Regression under Interval Truncation
In traditional linear regression, we try to recover a hidden model parameter $\vec w*$ with samples $(\vec x, y)$ of the form $y = \vec {w}^{*T} \vec x + \epsilon$, where $\epsilon$ is sampled from some noise distribution.
Huiwen Lu
,
Kanlin Wang
,
Yi Rong
,
Sihan Liu
Last updated on May 4, 2022
Statistics
,
Machine Learning
PDF
Code
Auto-MAP: A DQN Framework for Exploring Distributed Execution Plans for DNN Workloads
The last decade has witnessed growth in the computational requirements for training deep neural networks. Current approaches (e.g., …
Siyu Wang
,
Yi Rong
,
Shiqing Fan
,
Zhen Zheng
,
LanSong Diao
,
Guoping Long
,
Jun Yang
,
Xiaoyong Liu
,
Wei Lin
PDF
Source Document
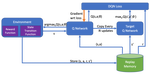
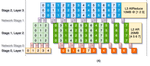
DAPPLE: A Pipelined Data Parallel Approach for Training Large Models
We propose DAPPLE, a synchronous training framework which combines data parallelism and pipeline parallelism for large DNN models. It features a novel parallelization strategy planner to solve the partition and placement problems, and explores the optimal hybrid strategy of data and pipeline parallelism. We also propose a new runtime scheduling algorithm…
Shiqing Fan
,
Yi Rong
,
Chen Meng
,
Zongyan Cao
,
Siyu Wang
,
Zhen Zheng
,
Chuan Wu
,
Guoping Long
,
Jun Yang
,
Lixue Xia
,
LanSong Diao
,
Xiaoyong Liu
,
Wei Lin
PDF
Code
Source Document
Cite
×