摘要
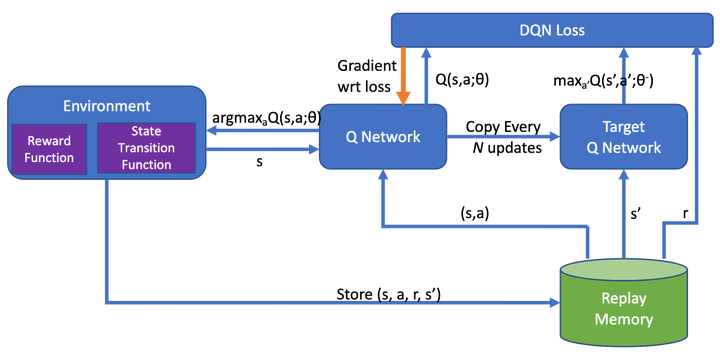
The last decade has witnessed growth in the computational requirements for training deep neural networks. Current approaches (e.g., data/model parallelism, pipeline parallelism) parallelize training tasks onto multiple devices. However, these approaches always rely on specific deep learning frameworks and requires elaborate manual design, which make it difficult to maintain and share between different type of models. In this paper, we propose Auto-MAP, a framework for exploring distributed execution plans for DNN workloads, which can automatically discovering fast parallelization strategies through reinforcement learning on IR level of deep learning models. Efficient exploration remains a major challenge for reinforcement learning. We leverage DQN with task-specific pruning strategies to help efficiently explore the search space including optimized strategies. Our evaluation shows that Auto-MAP can find the optimal solution in two hours, while achieving better throughput on several NLP and convolution models.