About
Welcome to my Academic site, where I share updates on my research projects.
2021 - now | I am a Master’s student at
![]()
![]() University of California, San Diego majoring in Computer Science & Engineering.
University of California, San Diego majoring in Computer Science & Engineering.
2020 - 2021 | Due to COVID-19 hardships and visa delays, I deferred my master’s to Fall 2021, and worked as a research intern at ![]() ByteDance AI Lab. I worked on several research projects on large-scale Machine Learning systems, DNN Compilers, and Automatic Parallelization algorithms.
ByteDance AI Lab. I worked on several research projects on large-scale Machine Learning systems, DNN Compilers, and Automatic Parallelization algorithms.
2019 - 2020 | In the 2019 school year, I was working as a year-round Research Intern at ![]() Alibaba Platform of AI (PAI), where I was lucky enough to work with a fantastic team on solving problems in the systems side of Machine Learning. My main focus was the automatic planning of Hybrid Parallelism strategy for Deep Learning.
Alibaba Platform of AI (PAI), where I was lucky enough to work with a fantastic team on solving problems in the systems side of Machine Learning. My main focus was the automatic planning of Hybrid Parallelism strategy for Deep Learning.
2016 - 2019 | I obtained my Bacholar’s degree at ![]()
![]() University of Wisconsin - Madison. In my undergraduate years, I double-majored in Computer Science and Mathematics there, and maintained both major GPAs above 3.91. I graduated with distinction in my junior year, 2019.
University of Wisconsin - Madison. In my undergraduate years, I double-majored in Computer Science and Mathematics there, and maintained both major GPAs above 3.91. I graduated with distinction in my junior year, 2019.
- Compilers
- Systems for Machine Learning
- Machine Learning for Systems
- PL Design
- Decentralized Network
- Any intersection of the above
-
M.S. in Computer Science, 2021-2023
University of California, San Diego
-
B.S. in Computer Science, 2016-2019
University of Wisconsin - Madison
-
B.S. in Mathematics, 2016-2019
University of Wisconsin - Madison
Experience
IR-level AutoParallel
- Designed and Implemented Automatic Parallelization on EIR
- Support models from TensorFlow, Torch/XLA, and JAX
- Fully automatic search of optimal solution [WIP]
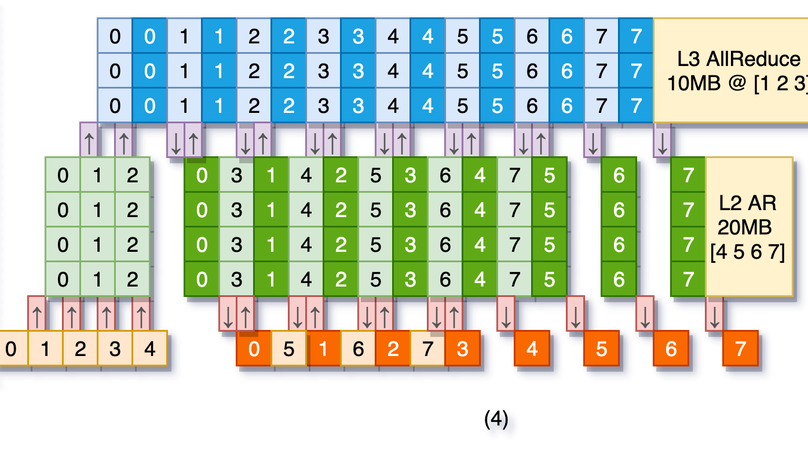
Large Model Training
- Collaboratively implemented a 3D hybrid parallelism framework for training large models, based on DAPPLE and DeepSpeed
- Able to train GPT3-175B at a significantly higher speedup compared to current solutions
- The framework is available in the company’s Arnold and VolcEngine platform
DAPPLE
- Designed and implemented a dynamic programming algorithm to search for the best data- and pipeline-parallel distributed strategy.
- Implemented the DAPPLE Runtime on TensorFlow
- Paper accepted by PPoPP'21
Auto-MAP
- Utilized reinforcement learning (DQN) to search for the hybrid parallel solution space
- Solve Auto Hybrid Parallelism problem on an IR (XLA HLO)
- Paper published as arXiv preprint
XLA AutoParallel
- Implemented a heuristic search based optimization algorithm for automatic parallelization on the TensorFlow XLA compiler.
AArch64 binary instrumentation & rewriting
- Implemented Dyninst AArch64 codegen for static rewriting
- Implemented Dyninst dynamic instrumentation on ARM64
Publications
Conference Papers, Journal Articles, and preprints
Reports
Course project reports and other drafts
WARNING: These are reports from various courses I have taken in the past, and are of much lower quality in terms of writing style and novelty than my formal publications.